
Update 1: I meant to have a place for people to leave comments on all of this, but messed up and can’t change it. You can make longer-than-tweet comments here if you like.
Update 2: I mistook TurkPrime to be an official Amazon-run blog. But I was corrected on this. In fact, it’s a third-party. (I was confused because the post says things like “In the coming days, we will launch a Free feature that allows researchers to block suspicious geolocations.”) Editing below to reflect this.
As some people have been talking about on Twitter and elsewhere (Kurt Gray; Max Hui Bai; Jennifer Wolak; me), some evidence is coming to light that survey data collected on MTurk is being compromised by problematic responses. Whether these are bots, inattentive responders, or something else is open for discussion. TurkPrme, a third party, recently discussed the problem, though for reasons I discuss below, I think they understate the extent of the issue. There is no official response from Amazon that I am aware of.
Yanna Krupnikov and I ran an experiment on MTurk in mid-July of 2018, and we see some evidence of problematic responses. Our instrument had four open-ended questions, which provide some extra purchase on what is going on. Here I transparently discuss the nature of the issue as it exists in Yanna’s and my dataset. As you’ll see, I conclude that there is fraud going on here, and that it almost certainly comes from a human-assisted computer algorithm. Skip to the end for the main takeaways.
Context
First, some necessary background on the study. Yanna and I are conducting a study of how aspects of political advertising affect implicit and explicit attitudes toward political advertising. The basic flow of the study is as follows:
- Immediately after being consented, participants are randomly assigned to one of three conditions. On this basis, they watch Version A of a ~4 minute video; Version B of the video, or no video at all (a control group). Both videos focus on a fictional candidate named Mike Harper.
- Participants are asked to write one sentence about what they usually have for breakfast. (A distractor task.)
- Then, in a separate random assignment, participants read Version A or Version B of a newspaper article.
- Participants complete an Implicit Association Test measuring implicit attitudes toward the candidate featured in the video. (This is done with the iatGen software.)
- Participants answer a number of other traditional survey questions: explicit affect toward the candidate, open-ended liking and disliking of the candidate; recall of content mentioned in the ad (if they watched an ad); and demographics. The survey closes with an optional open-ended item inviting any comments about completing the study.
There were 1,097 responses. Because a lower proportion of respondents generated useable IAT scores than we expected (which potentially relates to the issues described herein), we listed the study on MTurk twice. The initial invitation solicited 600 responses. A few days later, we solicited 400 more. (The total N is a bit above 1,000 due to people beginning the study–and perhaps not completing it–before accepting the MTurk HIT.) For the second posting, we excluded (via worker qualifications) MTurk worker IDs who completed the first posting, so (and this is key) no worker should have been able to complete the study twice.
It might be worth noting that the payoff scheme was different for the two postings. For the first posting, we paid $1.75 per HIT. For the second posting we paid $0.10 per HIT, but promised to bonus workers and additional $1.50 if they didn’t rush through the IAT.
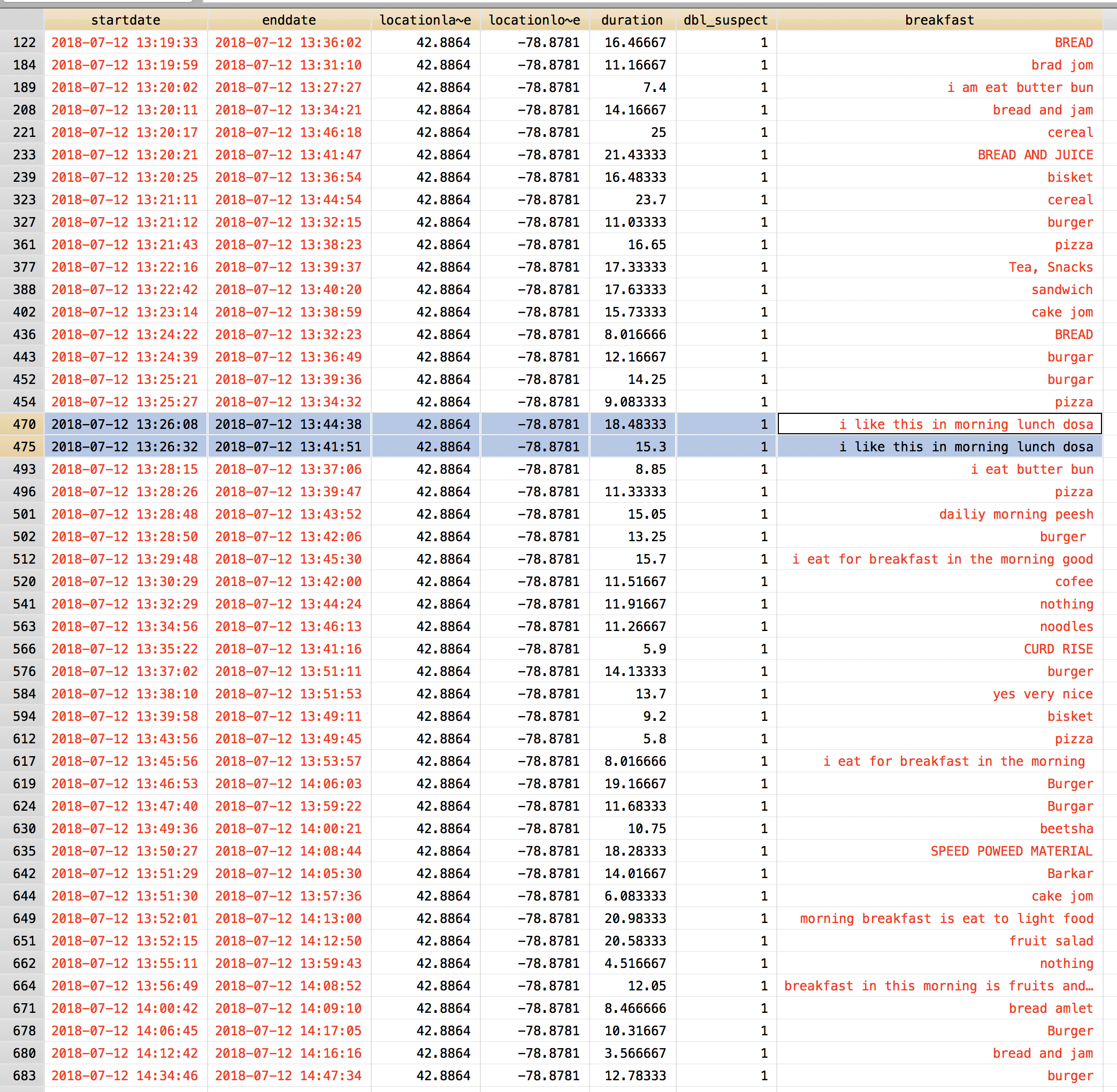
Repeated geographic information
Max Hui Bai posted that problematic responses appear to have repeated location coordinates in the geographic information that Qualtrics normally records. In our dataset, there is a fair bit of repeated geographic information in terms of latitude. The table below shows how many times there is a repeated latitude coordinate in our dataset. (So there are 570 latitudes that never repeat; 98 that repeat once, and so on.)
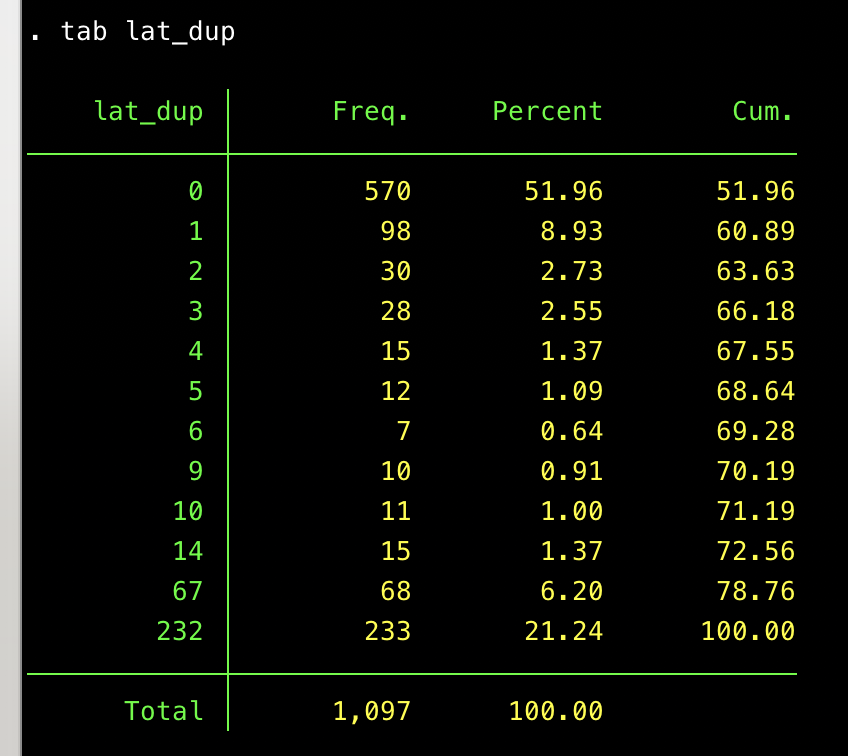
(Aside: Yes, I still use the green and yellow Stata theme. Some say it’s old. I say it’s timeless.)
I could show you duplicates in terms of longitude, but it’s basically the same thing. A Dummies for “latitude exists elsewhere in the dataset” and “longitude exists elsewhere in the dataset” have the same value in 1,092 out of 1,097 instances.
Two comments:
- The 570 locations that never repeat are good news. No suspicion generated there. I’ll be using these folks as a reference group going forward. Let’s call them geo_unique==1
- The one that repeats 232 times seems problematic, but I think it’s fine. These folks just have missing values for the geographical information. (I suspect that the information is hidden from Qualtrics, due to ISP, browser settings, or some other quirk.) Eyeballing their open-ended responses, they look high-quality to me. (They respond to the prompt, vary in terms of length and style.) Call this group geo_miss ==1
That leaves the ones in the middle, a total of 1,097 – (570+233) = 294 responses.
Max Hui Bai found that questionable responses in his dataset all had a particular character string (88639831) in the geographic information. When I looked for this string, I initially did not find it in my dataset at all. However, as I wrote this post, I realized that we have many occurrences of a slightly different one (88639832)–only the last digit is different. Flag these folks as huibai_sus == 1.
All the geo locations with the problematic string correspond to Buffalo, NY. Go figure.
The suspicious geographic string is localized in the big chunk of geographic responses that repeats 68 times:
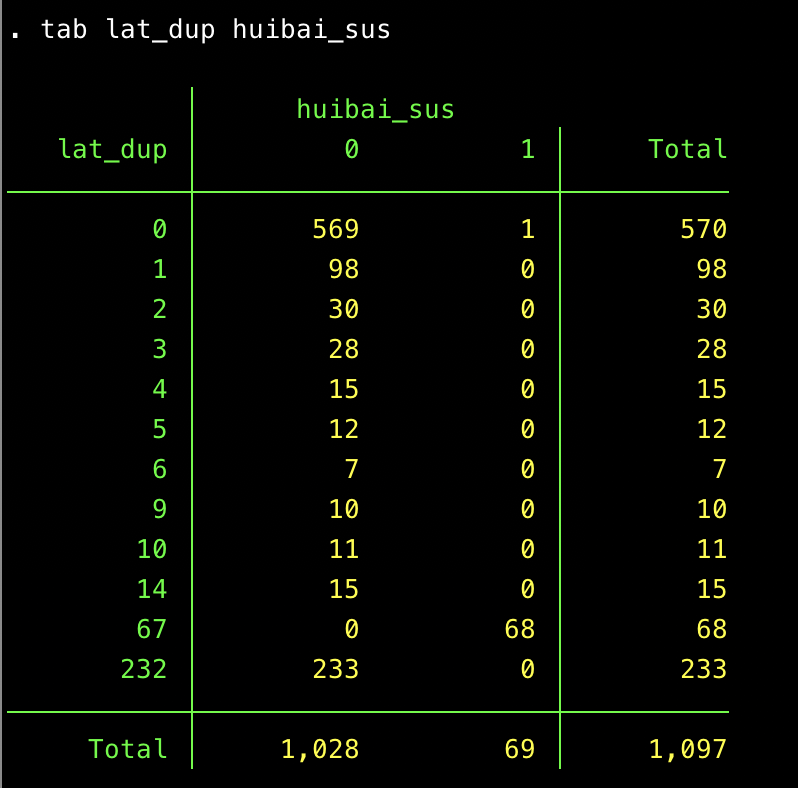
This pattern increases my suspicion toward those 68 responses, but makes me think that the geo locations that repeat fewer times might be fine. (I’ll examine them below.)
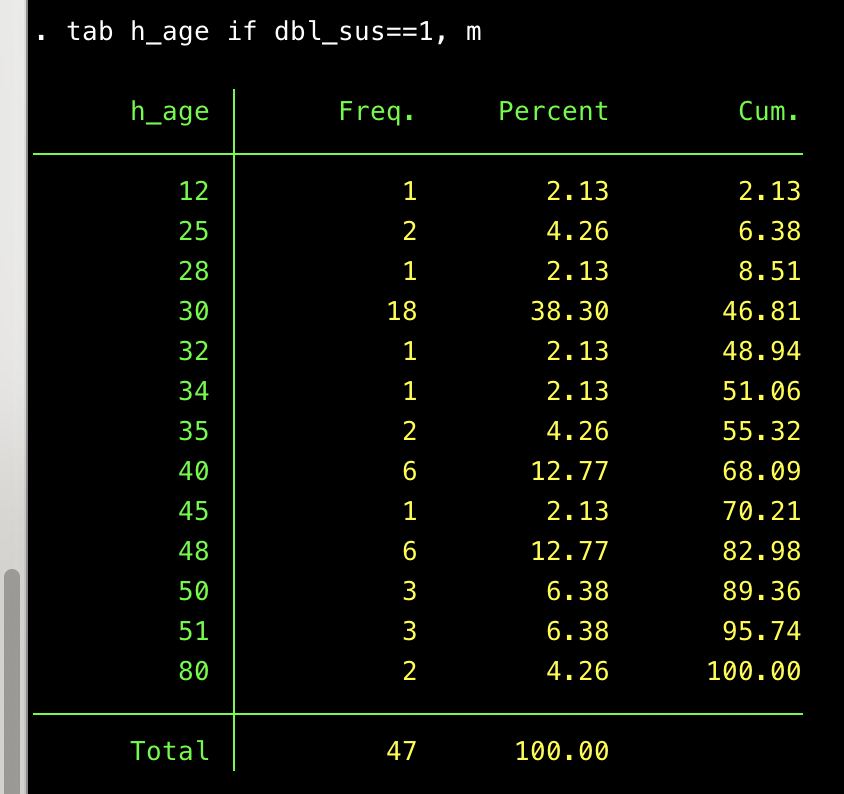
For no particular reason, I looked at the age distribution among the huibai_sus == 1 responses. It is funky!
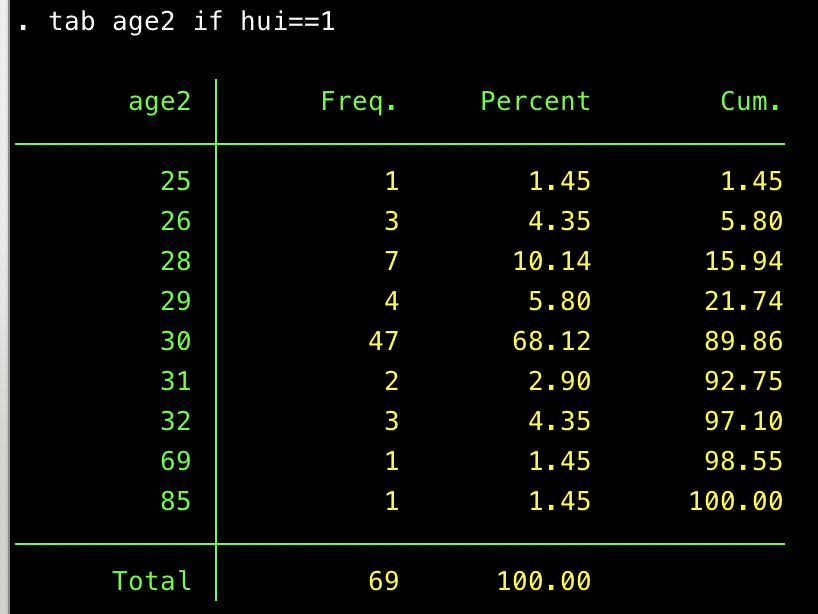
Sixty-eight percent of these folks say they are thirty years old. Age was measured with a blank open-ended text box (enter your age here), so this can’t be chalked up to a question default. This result made me certain that something weird is going on here. Call those 47 responses dbl_suspect==1. Based on other survey responses, 46 of the 47 people say they are male, which also seems problematic. (The one who doesn’t claim to be male skipped the gender question.) However, they have varied responses to other questions. (More on that below.)
Open-ended responses from the suspicious response rows
Let’s look at their open-ended responses and see how they behave.
First the Debriefing question. Here are all 47 responses:

These look problematic. It is NOT common for the one-word responses (good, nice) to come up so frequently in the rest of the dataset. At the same time, if these responses purely came from a computer, I’d expect them to look a bit different than they actually do. Here is a distribution of the responses:
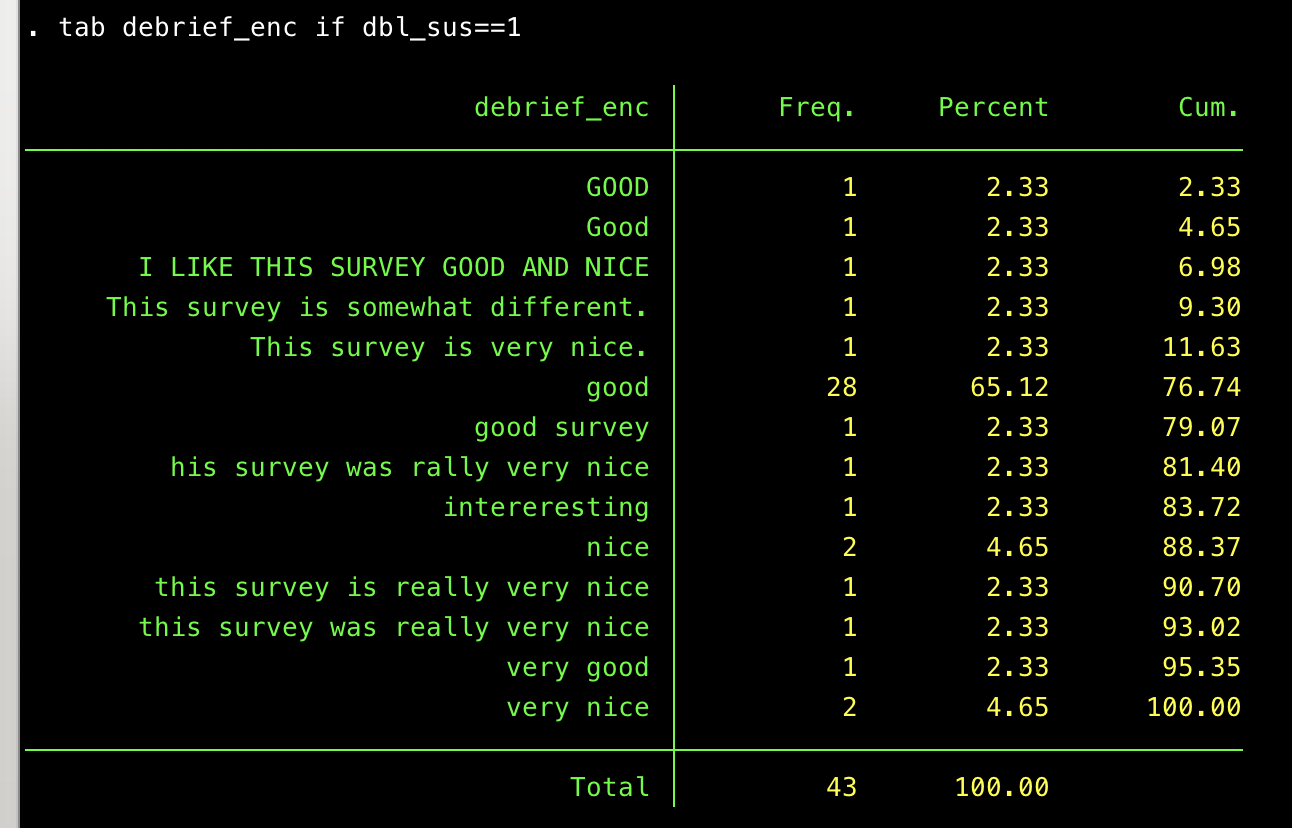 If this is an algorithm, it’s one that inputs “good” with probability ~66%, but then varies widely for the other 34%. (And yet even in those varied responses, there are hints that they come from the same entity–e.g. the repeated “really very nice” phrasing.)
If this is an algorithm, it’s one that inputs “good” with probability ~66%, but then varies widely for the other 34%. (And yet even in those varied responses, there are hints that they come from the same entity–e.g. the repeated “really very nice” phrasing.)
Let’s look at more open-ended responses. As I noted, we asked about likes and dislikes toward the fictional candidate Mike Harper. Here are the likes:
And here are the dislikes:

Lots to talk about here. Some observations:
- First, compared to the rest of the dataset, these responses are unquestionably crappy. By and large, the others show a lot more care and attention.
- SOME of the responses show a modicum of attention to the study. For instance, Like #32 is a reasonably coherent thought. And it notes that Harper is a candidate for Congress, a history teacher, and teacher as a high school in Statesville. All these details come from the video that participants watched. They cannot be from Googling.
- However, there is spillover. That same response 32 says that Harper resigned his position. That’s true–but only in one experimental condition, and not the condition that this response was actually assigned. (!) This is a dead giveaway that one entity (person, bot, whatever) is generating more than one row in the dataset.
- Some of the responses basically repeat, although typically masked with a little variation. E.g. Like #24 is “i like mike harper habbit and style..”, but like #29 is “like it mike harper habbit. like also style”
- Some of the responses show no attention to the survey at all. Of course there some are just “yes” or “no.” But Like #12 is plagiarized from the wikipedia page for a different Mike Harper. Like #6 has nothing at all to do with the study and is plagiarized from this website, which has no connection to Mike Harper that I can perceive.
This is all baffling to me because the deception seems to take so many different forms: sometimes randomly perturbing a generic response that actually has to do with the study. Sometimes googling things related to the study. Sometimes inputing completely unrelated text from a random website.
Perhaps also worth noting: open-ended are responses share some of the same characteristics within-row of the dataset. For instance, Like #1 is in ALL CAPS. Likewise, this rows responses for the breakfast, disliking, and debriefing question are also all caps.
What about open-ended responses from the N=22 responses who have the suspicious geographic information, but did NOT report their age to be 30? I’ll share these upon request, but I’d say they look equally suspicious as what I show above.
Alarming Finding: Equally Duplicitous Responses Don’t Always Repeat Geographical Information
Next, I asked, Do the suspicious responses always give me a geo location with the string that Hui Bai found–the one that appeared 68 times in my dataset? If so, they are pretty easy to catch and exclude. But I’m concerned that I’ve found evidence that our nemesis (dear readers) is even craftier than that.
Recall that a large proportion (though not all!) of the suspicious responses to my “any comments?” debriefing question were single words: good and nice. Let’s flag just those responses:
gen debrief_lc = lower(debrief) // standardize to lower case
gen debrief_sus = 0
replace debrief_sus = 1 if debrief_lc==”good” | debrief==”nice”
There are 64 such responses, including 20 that did not have the suspicious geo string:
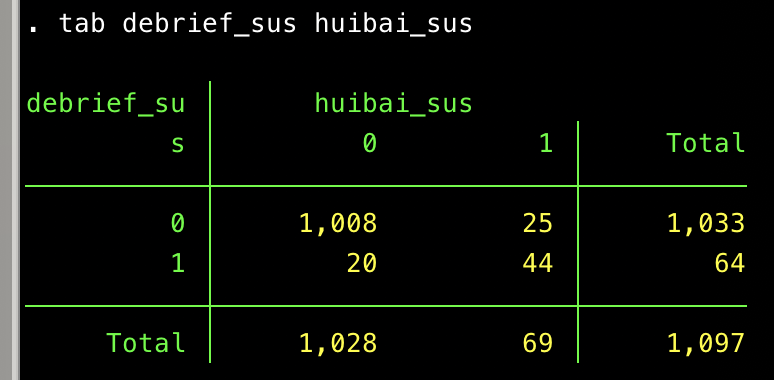
That’s disconcerting! Well, maybe legitimate responses just coincidentally use those words. Maybe a few do, but I see our nemesis’s fingerprints here, too. Look at the age distribution among these 20 folks. Here again, there is a spike at 30 years old:
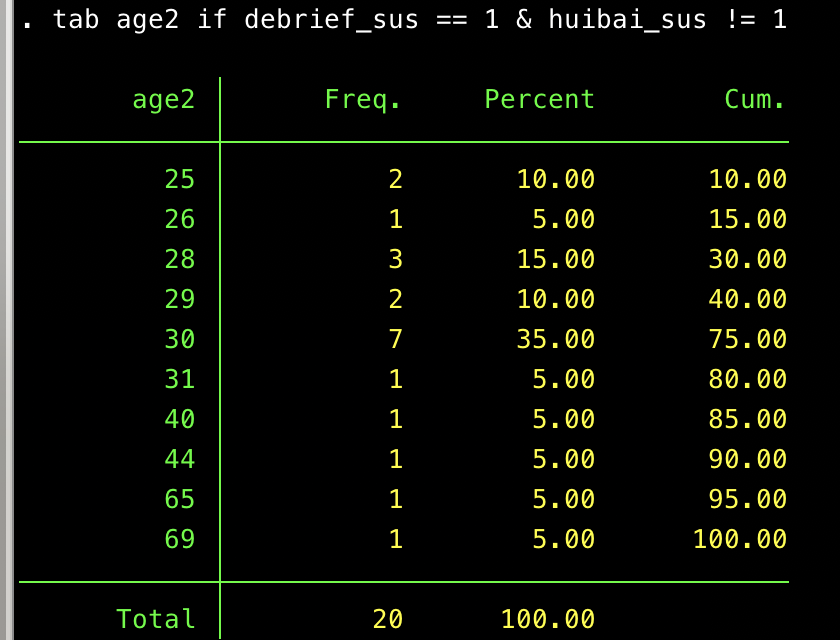
And they are disproportionately male:

And their open-ended responses look problematic in similar ways as the ones reviewed above:
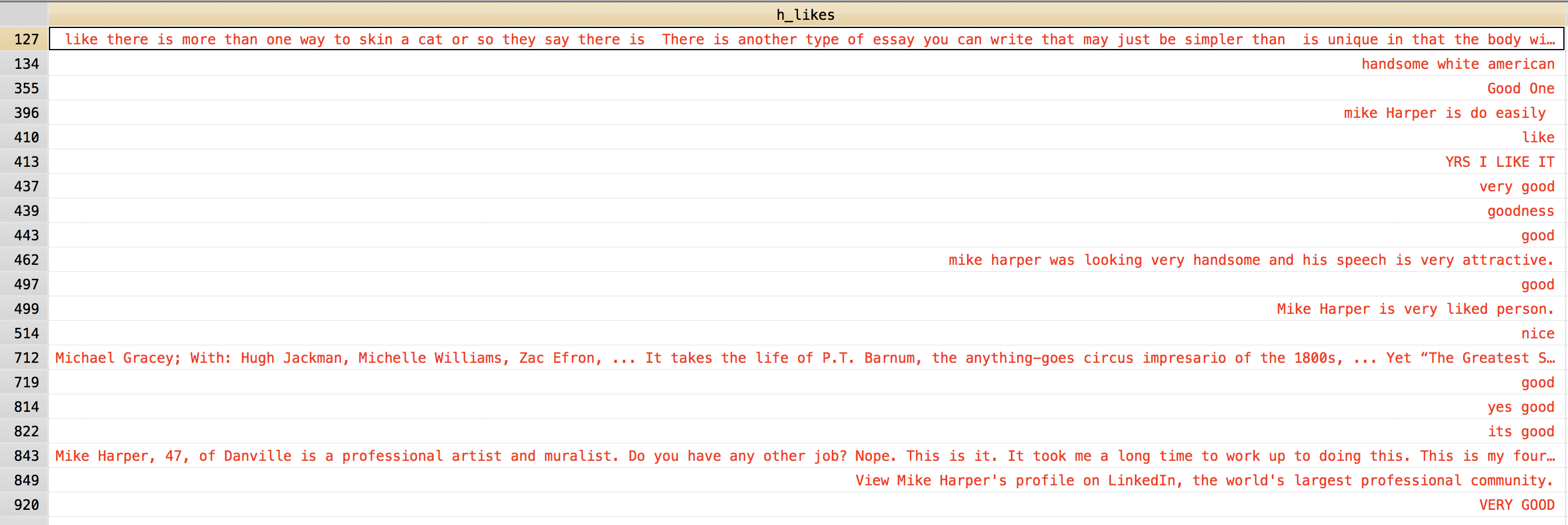
Like #127 in that image bears special note. It is plagiarized from the same random website that was used in one of the huibai_sus==1 responses I examined above. But it’s geo code corresponds to an obscure place in Texas. This makes me worry that, although the problematic responses come disproportionately from Buffalo, there might be several that come from other places.
Response #410 in the image above is especially concerning. This response has all the calling cards of a problematic response: the response to the debriefing question is “good.” The responder purports to be a 30 year old male. The other open-ended responses are bad. The person button-mashed through the IAT, generating an unusable score. Yet the geo-code (36.172, -115.2094, which corresponds to Las Vegas) appears only one additional time in the dataset. The other response also appears duplicitous. But as I return to below, the fact that our nemesis generated only two instances of this geocode is disconcerting. There appear to be many legitimate responses that also, just by coincidence, have a geocode that coincides with someone else in the dataset. (It’s not so surprising that two legitimate responses would be geographically proximate to each other, or at least to have network information that implies this.) So if we dropped any rows for which the geocode repeats somewhere else in the dataset, we’d have a lot of false positives. (Would drop a lot of legitimate responses.)
Other properties of the contaminating responses
Let’s return to the 47 dbl_suspect==1 folks mentioned above. As a reminder, these folks have the suspect geocode from Buffalo. They all claim to be 30 years old, and all but one claims to be male. I’m confident that these responses are fake. (Though I’m also sure that some fake responses are not captured by this flag.) How do these folks behave in other respects? There are some interesting patterns.
First, they vary widely in how long they take to complete the survey: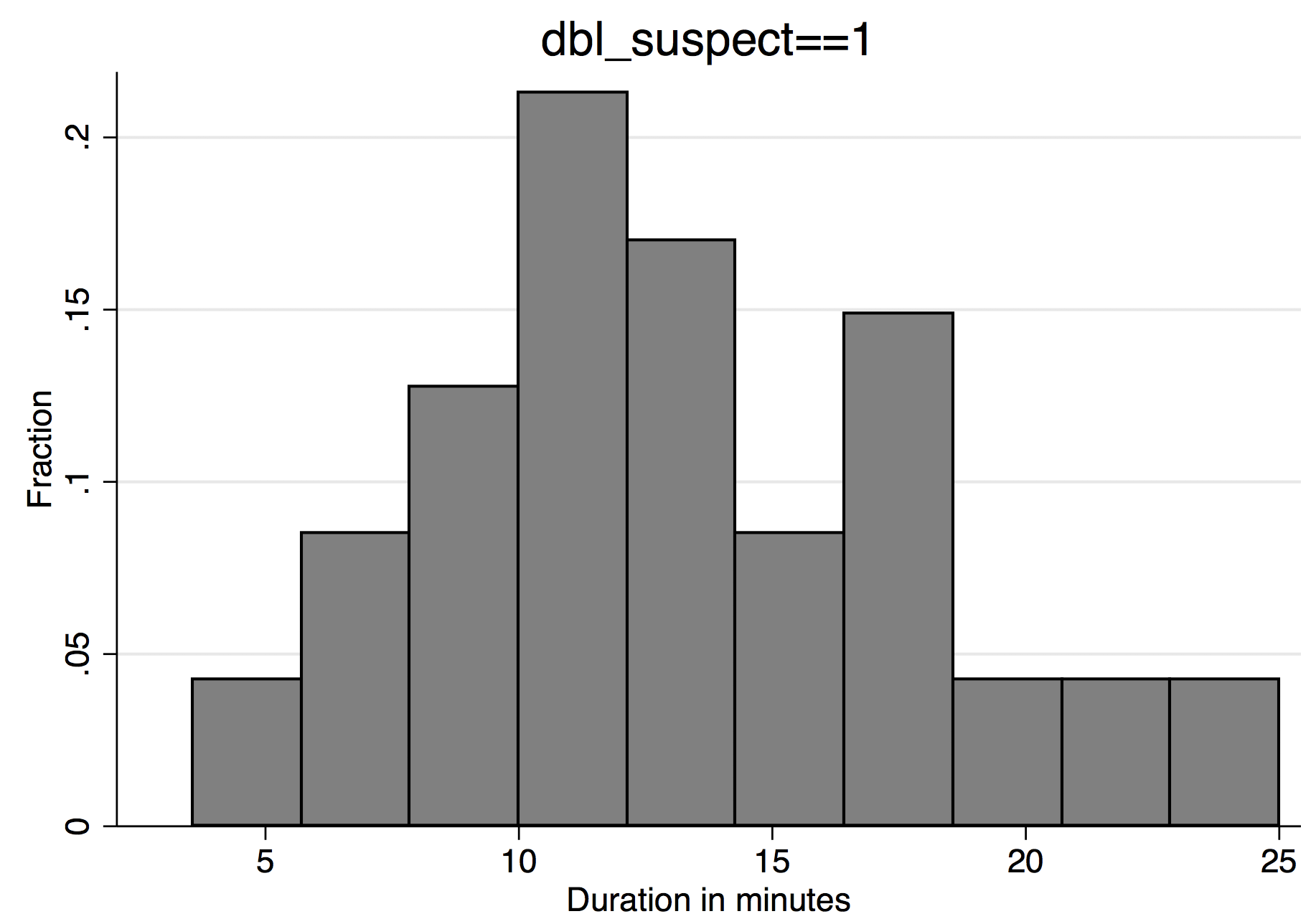
This is quite surprising behavior, if these responses came from a robot. It’s a robot that sometimes goes fast, and sometimes goes slow.
Second, many of the responses were coming in at the exact same time. Consider the highlighted rows in the image below. Clearly, these are fake responses: the answer to the breakfast question is identical. But based on the time stamp, they were being entered simultaneously. This makes me almost positive that what’s going on here is, if not a bot, at least bot-subsidized.
As I mention above, the study included an IAT, a somewhat onerous procedure that someone trying to game MTurk for money would be eager to skip through. We initially intended to collect 600 responses, but collected ~400 more after we observed that being were “failing” the IAT (generating unusable scores because they button-mashed through the task–defined as having >10% of IAT responses faster than 300miliseconds) at a high rate. In a parallel study on a different (not MTurk) sample, only ~3% of respondents had invalid IAT scores. In MTurk, the failure rate was around 30%–both when we incentivized careful responding and when we did not. (The incentive made no difference.)
I now realize that the IAT failures are substantially attributable to these duplicitous responses. Of dbl_suspect==1 respondents, 100% had invalid IAT scores. Of the 64 folks with suspicious debriefing responses, 86% had invalid IAT scores. Based on open-ended responses, the remaining 14%, still look suspect to me. I infer that the nemesis typically (but does not always) fail the IAT.
Since the nemesis typically seems to fail the IAT, it is instructive to look at the IAT failure rate, depending on how many times a geocode is repeated in the dataset:
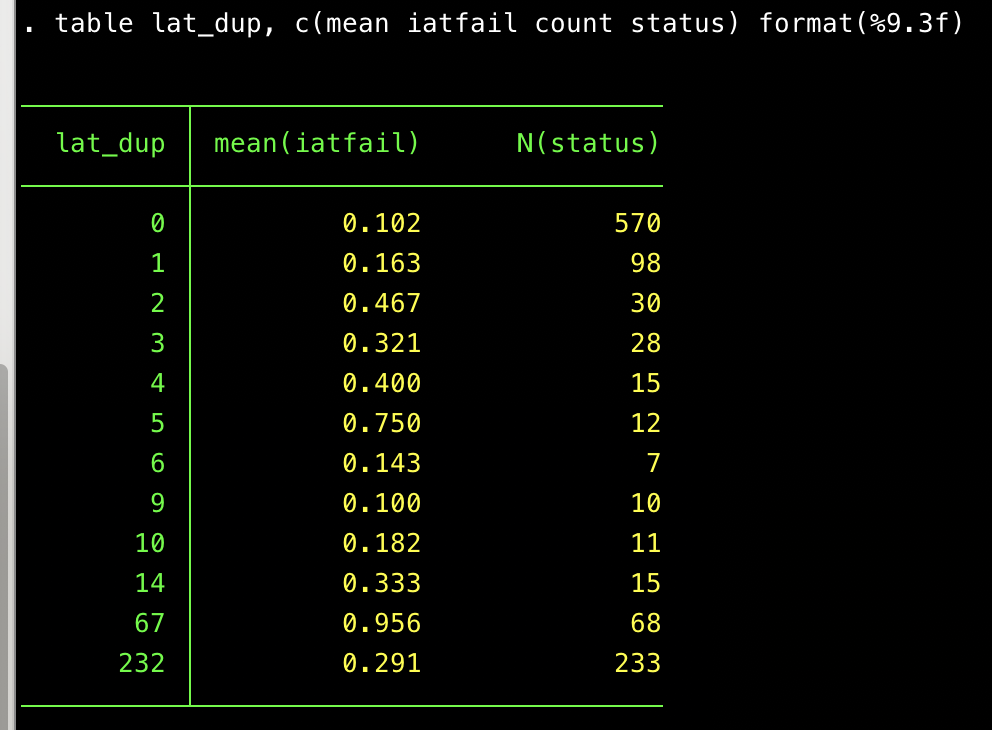
This table shows that, for the geocode that appears 68 times (67+1) in the dataset–the suspicious one from Buffalo–the IAT failure rate was 95.6%. Among geocodes that were unique, the failure rate was only 10.2%. Unfortunately, the levels in-between–especially the relatively low failure rate among geo codes that repeat only once–suggest to me that these represent a mixture of real and fake responses. So again, it will be hard to use geocodes to purge all the fake responses.
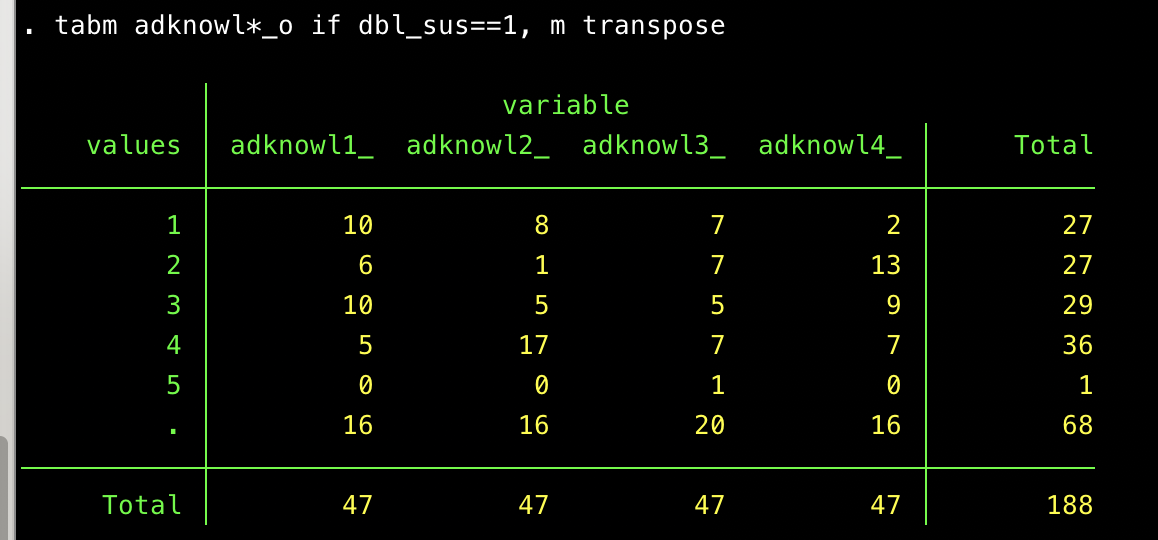
When asked (in closed-ended format) how well various descriptors apply to Mike Harper (educated, a leader, experienced, etc.), the dbl_susp==1 responses often choose one of the higher options. Sometimes they skip the question. They never choose one of the lowest two response options (which would have had values of 0 or .25):

When asked to guess Mike Harper’s age in years (in open-ended format) these responses are disproportionately–but not always–30. (There it is again!)
We also asked participants to guess Harper’s 1) ideology and 2) Party affiliation. Interestingly, these responses are convincingly correlated in a reasonable way–such that nemesis-responses that say Harper is a Democrat also tend to say he’s liberal. And vice-versa for Republican:

Note that that represents interesting (though probabilistic) within-response consistency.
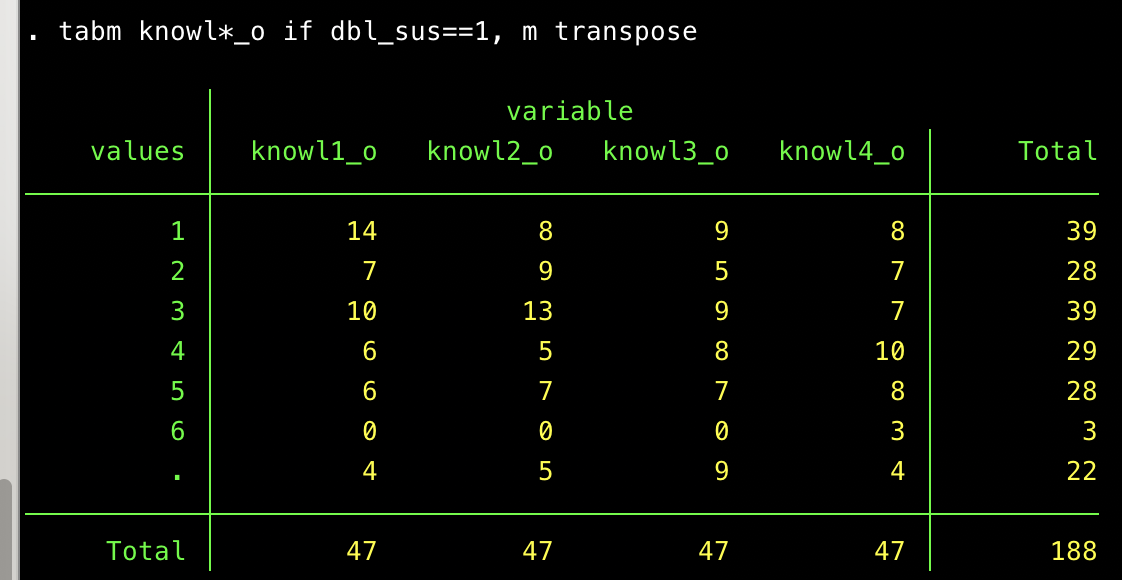
We also asked respondents a series of political knowledge questions. Responses to these appear more or less random to my eye:
Similar for four questions measuring recall of the ad
Key takeaways, and a notes on TurkPrime’s response
The results above are instructive for figuring out how to detect problematic responses in existing data and think about how to address this problem going forward. Here are some key takeaways:
- A single entity (human, bot, whatever) is generating multiple responses through the MTurk platform. I am confident concluding this because of the repeated patterns that arise in separate rows of my dataset–including verbatim text, and cognizance of material from one experimental condition, even when assigned to the other. Note that this is at odds with a possibility that TurkPrime entertains–namely that these are all real individuals who have identical geocodes because of how they are using a VPN.And it points to a deeper issue. My understanding is that MTurk workers based in the US need to provide a Social Security number (or other taxpayer identification) to register their accounts. Since all the responses in our dataset are from unique MTurk accounts, it appears that a number of these accounts are fraudulent and need to be purged.
- The extent of data contamination is substantial. TurkPrime estimates that, in most samples, the extent of contamination is 2.5% or less, though it allows that there has been an increase lately. Based on the information above, I’m confident in that at least 9.38% of the responses in our dataset are fraudulent. This is the lower bound–I suspect there are some that are harder to detect, because they lack some of the dead giveaways, which leads me to…
- The problematic responses are sophisticated in some ways, stupid in others. In some ways, the fraudulent responses are very sneaky. The open-ended responses pass a quick glance, because several are responsive to the question in some minimal way, and when they ignore the question, they do so in at least three different ways: writing something short and meaningless (“yes”); googling something related (wikipedia page for a different Mike Harper); and googling something unrelated (pumping in text from a totally irrelevant website). For closed-ended responses, there appears to be a stochastic element–but one that is constrained. (See the correlation above between a guess of Harpers partisanship and his ideology.) The fraudulent responses sometimes are fast, and sometimes they are slow. (See the duration histogram above.)And yet this sophistication notwithstanding, the fraudulent responses do some things surprisingly bluntly: answering “30” to age questions at a highly elevated rate, and answering “male” to a gender question almost all the time.
- There is no obvious way to purge all fraudulent responses.At least not one I can think of. It seems like there are some things that are a sufficient condition for saying that a response is fraudulent–but not a necessary condition. I suspect 100% of the Buffalo geo codes that Hui Bai caught are fraudulent. I suspect nearly 100% of the one-word (“good”, “nice”) debrief responses are fraudulent. But I can point to several instances of responses that are fraudulent–seemingly from the same source–but which do neither of these things. Some (e.g. the Addison, Texas response above) have geo codes that appear only twice in the dataset–and many legitimate responses also have geo codes that appear twice. So it’s very difficult to sort the wheat from the chaff.
- The fraudulent responses almost certainly have human guidance, but computer-based assistance (a bot).As I note above, the of the fraudulent responses definitely show attention to a video that was part of our study. That makes it all but certain that a human is at work here.And yet, there is also equally conclusive evidence that a computer is helping, too. For instance, I find evidence of verbatim responses coming from survey that were concurrently under way.